Nel mondo aziendale moderno, dove i dati viaggiano a velocità sempre più elevate, la capacità di estrarre rapidamente informazioni chiave da documenti non strutturati rappresenta un vero vantaggio competitivo.
SAP Document Information Extraction (DIE) è una soluzione intelligente progettata per affrontare proprio questa sfida, automatizzando la lettura e la comprensione dei documenti aziendali più comuni.
Ma quanto è efficace rispetto ad un sistema di intelligenza artificiale generico come ad esempio ChatGPT? Perché scegliere di utilizzare SAP DIE invece di un servizio pubblico, accessibile a tutti e apparentemente più flessibile?
Lo scopriremo nel corso di questo articolo, attraverso un confronto pratico e un caso d’uso reale.
Cos’è SAP Document Information Extraction?
SAP DIE è un servizio basato su machine learning che consente di automatizzare l’estrazionedi informazioni chiave da documenti aziendali.
È sufficiente caricare il documento: il sistema riconosce automaticamente campi chiave come intestazioni, date, importi e codici. I dati estratti vengono archiviati in un file JSON, pronto per essere interrogato e integrato nei sistemi aziendali.
Come funziona?
Dopo aver caricato un file, SAP Document Information Extraction esegue i seguenti passaggi:
• Controlla se il documento è in formato Factur-X o ZUGFeRD; in tal caso, estrae i dati strutturati contenuti al suo interno.
• Controlla la presenza di altri dati leggibili automaticamente, come quelli presenti nei codici a barre; se presenti, estrae tali informazioni.
• Invia il documento al riconoscimento ottico dei caratteri (OCR) per estrarre tutti gli altri dati.
• Infine, archivia le informazioni estratte dal documento in un file JSON che è possibile interrogare.
Che tipologia di documenti supporta per l’estrazione?
schemi e template personalizzati per estrarre correttamente le informazioni.
SAP Document Information Extraction supporta i seguenti tipi di documento:
Tipi di documento standard: fanno riferimento ai documenti per i quali SAP fornisce modelli di apprendimento predefiniti che permettono un’estrazione automatica delle informazioni senza configurazioni preliminari. Ad esempio:
o Fatture
o Avvisi di pagamento
o Ordini d’acquisto
Tipi di documento personalizzati: fanno riferimento ai documenti per i quali SAP non fornisce modelli di apprendimento predefiniti. In questo scenario, è possibile configurare schemi e template personalizzati per estrarre correttamente le informazioni.
Che tipi di file supporta?
SAP DIE supporta diversi formati di file in base al piano sottoscritto. Di seguito, tutti i formati
supportati per i tipi di documento standard
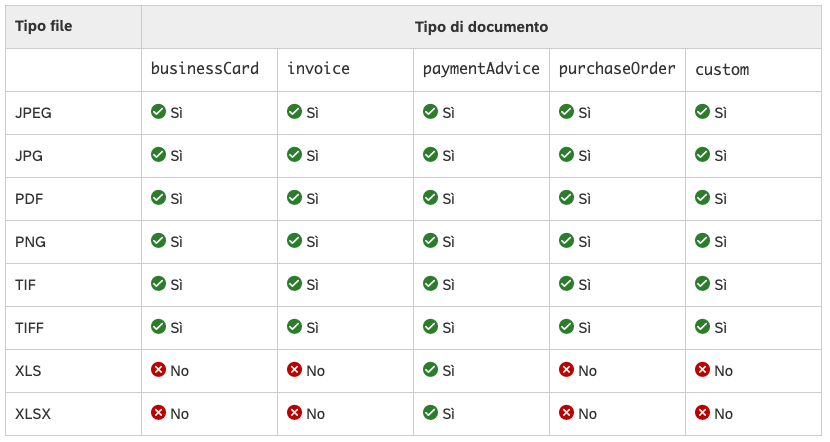
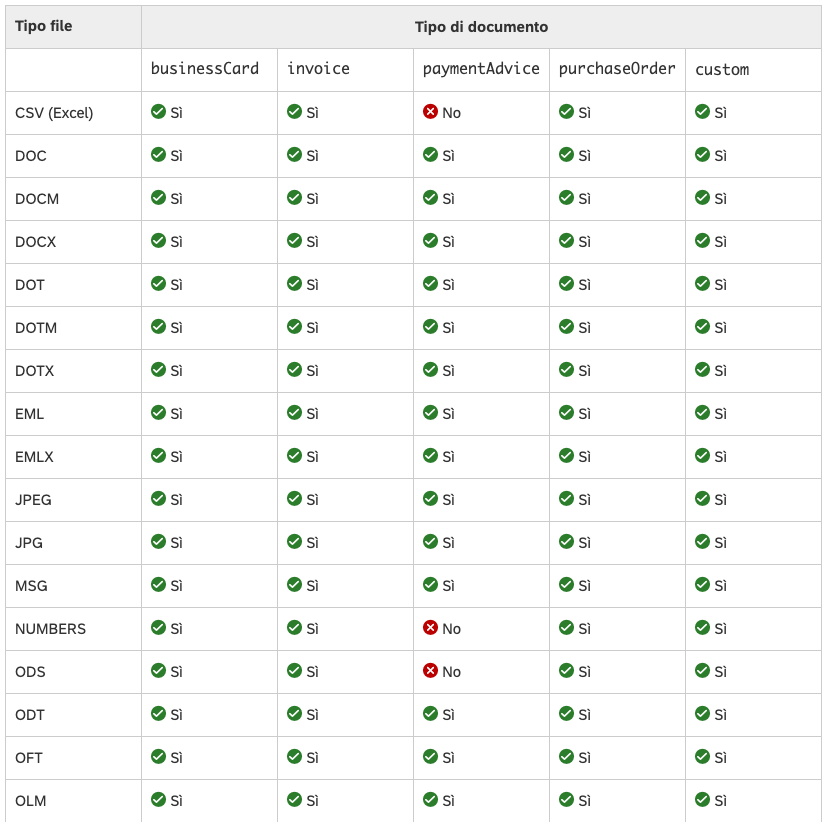
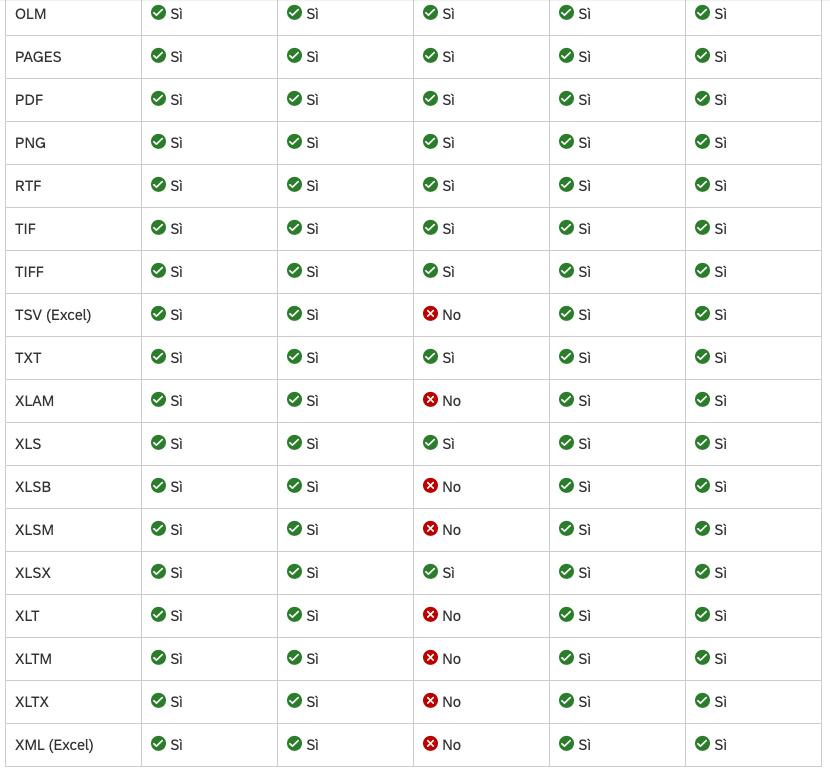
Alcuni concetti di SAP DIE
Apprendimento istantaneo: è una funzionalità (Premium Edition) che utilizza il feedback degli utenti per migliorare la qualità delle estrazioni: quando gli utenti modificano i risultati di un’estrazione per un documento e confermano i propri inserimenti, il servizio apprende immediatamente da questo feedback. Di conseguenza, la qualità delle estrazioni successive migliora.
Schema: è una raccolta di campi che viene utilizzata durante il processo di estrazione. Definisce i campi che devono essere estratti da un documento. Gli schemi SAP sono raccolte preconfigurate di campi per documenti standard, ma possono essere copiati e utilizzati come base per la creazione di schemi personalizzati. Inoltre, forniscono la base per la creazione di template.
Template: è uno strumento progettato per ottimizzare l’estrazione dei dati da documenti con layout specifici, attraverso la creazione di template personalizzati. Dopo aver creato un template, è possibile associare uno o più documenti ad esso. Successivamente, si elaborano i risultati delle estrazioni per questi documenti, indicando l’ubicazione dei campi e i relativi valori. I template sono essenziali per estrarre informazioni da documenti personalizzati, ma possono essere utilizzati anche con documenti standard per migliorare l’accuratezza dell’estrazione.
Intervallo di confidenza: è un intervallo che indica l’accuratezza dei risultati dell’estrazione. Questi intervalli di confidenza sono codificati in base al colore: il rosso indica una probabilità bassa (da 0% a 50%), il giallo indica una probabilità moderata (dal 51% al 79%) e il verde indica una probabilità alta (dall’80% al 100%). Se l’intervallo di confidenza è basso o moderato, gli utenti dovrebbero controllare e, se necessario, correggere i risultati dell’estrazione per i campi in questione.
Confronto: SAP Document Information Extraction vs ChatGPT
Abbiamo provato ad estrarre i dati da una tipica fattura in formato PDF , confrontando due approcci differenti. Da un lato, uno strumento di intelligenza artificiale generico e accessibile al pubblico, come ChatGPT. Dall’altro, il servizio specializzato SAP Document Information Extraction. L’obiettivo era quello di valutare quale dei due approcci offrisse le migliori prestazioni in termini di accuratezza, struttura dei dati ed efficienza operativa. Di seguito la fattura utilizzata:

ChatGPT
La seguente immagine mostra il prompt utilizzato in ChatGPT per estrarre i campi principali dalla fattura.
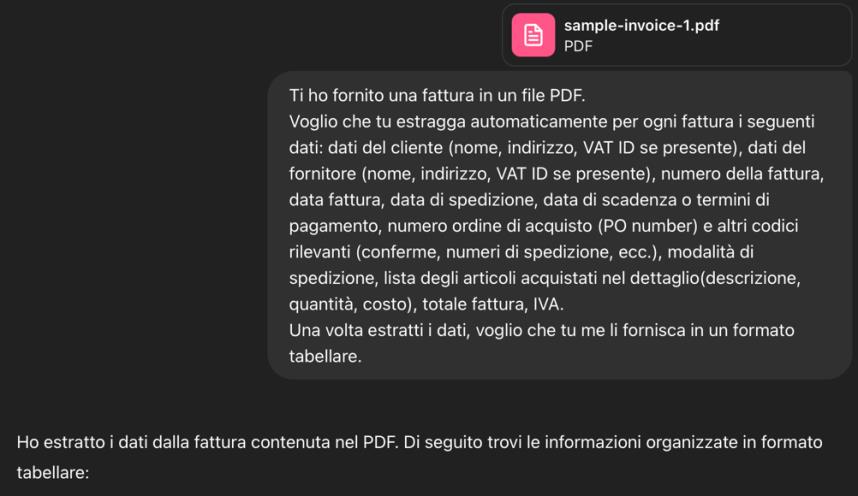
Le immagini seguenti mostrano i risultati dell’estrazione effettuata.
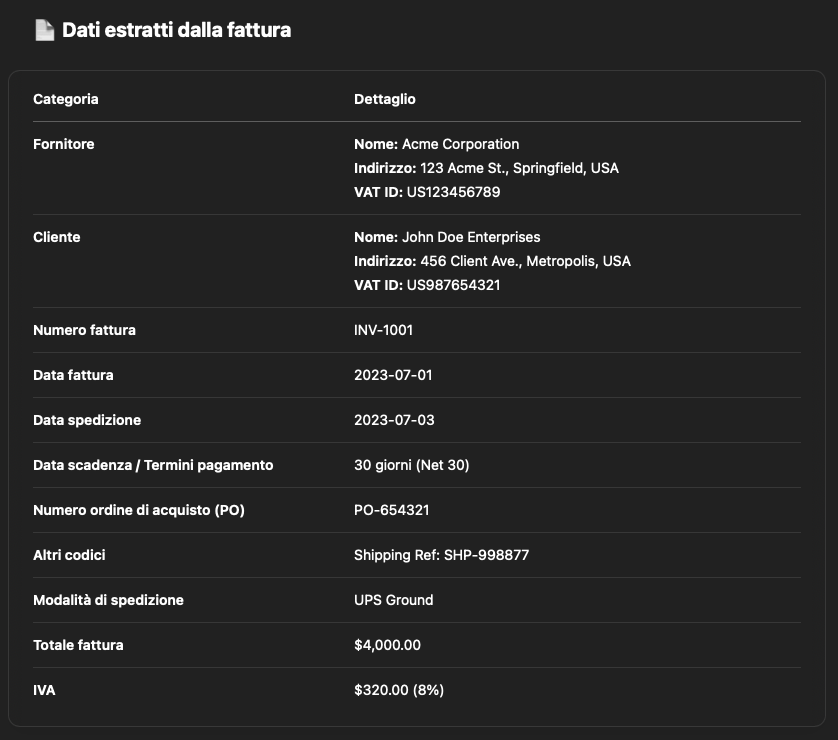
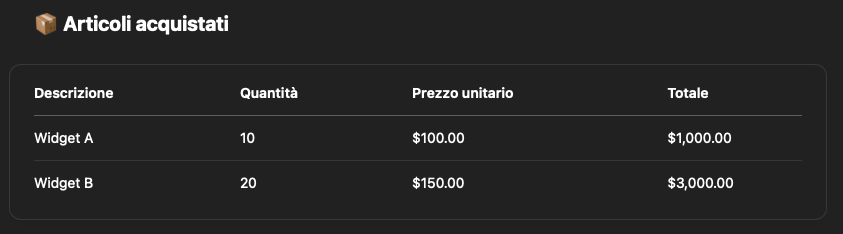
Nonostante l’impiego di un prompt chiaro, strutturato e mirato, ChatGPT ha restituito un risultato incoerente: alcuni dati sono stati omessi, altri interpretati erroneamente e diversi campi sono stati letteralmente inventati. Questo comportamento è riconducibile alla natura del modello, pensato per generare testo in linguaggio naturale piuttosto che per leggere documenti strutturati. L’assenza di una comprensione del layout, l’impossibilità di riconoscere visivamente le sezioni del documento e la tendenza a “riempire i vuoti” portano a risultati inaffidabili in scenari di questo tipo.
SAP Document Information Extraction
Al contrario, SAP Document Information Extraction ha processato correttamente la fattura, identificando tutti i campi rilevanti e restituendo un output strutturato in formato JSON, pronto per essere processato.

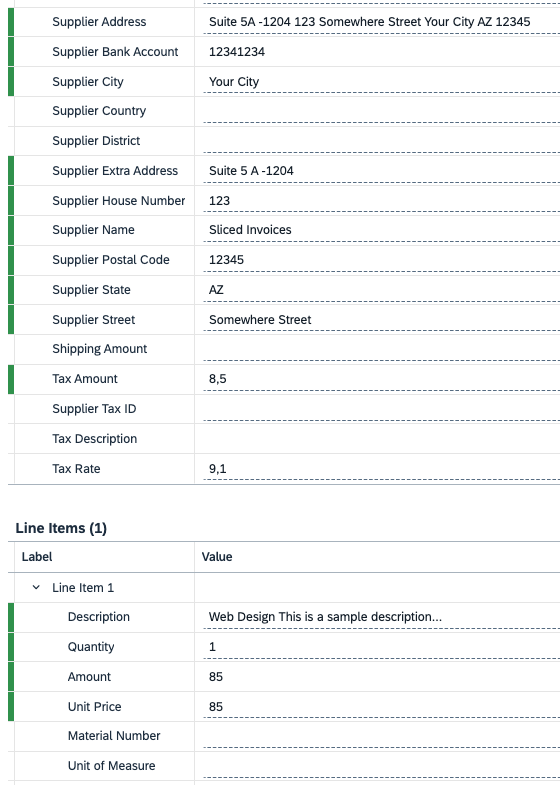
Di seguito la visione completa della schermata:
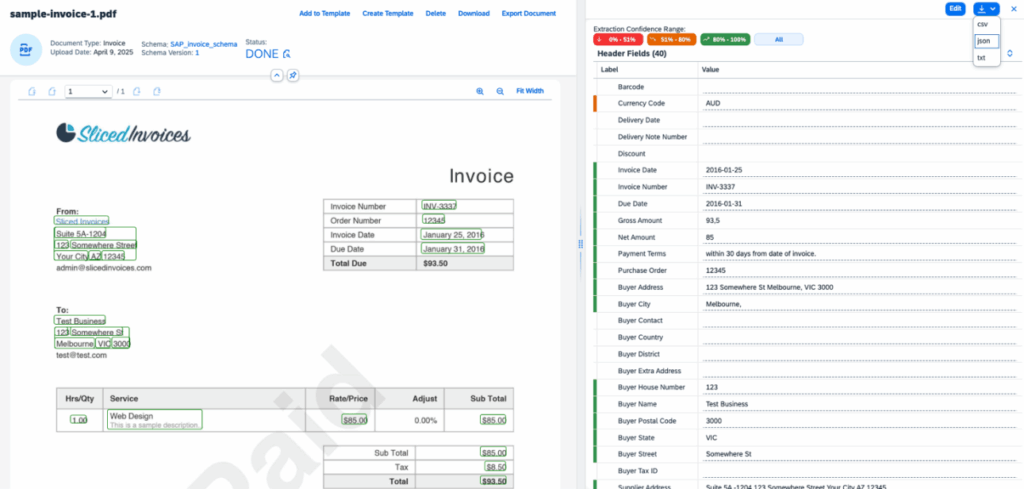
Una delle differenze principali è che SAP DIE non richiede alcuna istruzione manuale per comprendere il contenuto del documento: è stato sufficiente caricare il file e il sistema ha estratto automaticamente i dati. Questo è possibile grazie al supporto nativo per documenti standard come ad esempio le fatture, per i quali SAP fornisce modelli predefiniti già ottimizzati per l’estrazione.
Considerazioni finali
Per questa fattura, i dati estratti da ChatGPT sono completamente errati. Inoltre, ChatGPT:
• Necessita di un prompt chiaro e preciso: se il prompt non è ben definito o il documento cambia struttura, l’accuratezza dell’estrazione può calare drasticamente.
• Non è progettato per gestire grandi volumi di documenti in modo scalabile. Per processare migliaia di documenti al mese, sarebbe necessario scrivere script personalizzati per automatizzare l’interazione con ChatGPT e gestire le risposte, aumentando il carico di lavoro e i costi.
• Di default, restituisce risposte in formato non strutturato. È possibile ottenere un output strutturato, come ad esempio un JSON, ma solo fornendo un prompt mirato. Tuttavia, anche in questi casi, la coerenza e l’accuratezza della struttura non sono garantite: l’output può contenere errori di formattazione, campi mancanti o non allineati alle specifiche richieste, rendendo necessario un controllo o una correzione manuale prima dell’utilizzo in ambienti aziendali.
• Utilizzare ChatGPT per l’estrazione di dati sensibili potrebbe sollevare preoccupazioni in merito alla privacy e alla sicurezza dei dati. Le informazioni estratte potrebbero essere inviate ai server di OpenAI per il trattamento, esponendo i dati aziendali a potenziali rischi di violazione della privacy.
SAP Document Information Extraction, al contrario, è stato progettato proprio per questi scenari:
• Non sono necessarie configurazioni iniziali. L’utente non deve definire regole o fornire istruzioni dettagliate, SAP DIE funziona in modo predefinito e automatico per molti tipi di documenti standard.
• Fornisce un output già strutturato in formato JSON, pronto per essere elaborato e integrato in sistemi aziendali, riducendo significativamente il tempo e gli errori nel processo di importazione.
• È stato addestrato su una vasta gamma di documenti reali, provenienti da diversi settori e casi d’uso, permettendogli di adattarsi a una varietà di formati e layout. Questo addestramento permette a SAP DIE di estrarre dati con un alto grado di precisione, garantendo coerenza tra documenti simili e riducendo al minimo gli errori.
• È progettato per lavorare all’interno di un ecosistema aziendale privato, garantendo che i dati sensibili rimangano al sicuro e sotto il controllo dell’azienda.ChatGPT è uno strumento estremamente potente, ma progettato per altro. Quando si parla di estrazione automatizzata di dati da documenti aziendali, mostra alcune limitazioni significative. Queste possono tradursi in maggiori costi operativi, necessità di frequenti interventi manuali e una gestione più complessità, soprattutto in contesti aziendali con un alto volume di documenti da elaborare.
SAP Document Information Extraction, al contrario, è progettato proprio per affrontare queste fide. Offre una soluzione verticale, solida e scalabile, pensata per garantire un’elaborazione automatica dei dati efficiente e affidabile. Questo confronto evidenzia chiaramente come, per contesti aziendali, una soluzione come SAP Document Information Extraction rappresenti una scelta decisamente più efficace rispetto a strumenti generalisti come ChatGPT.
